



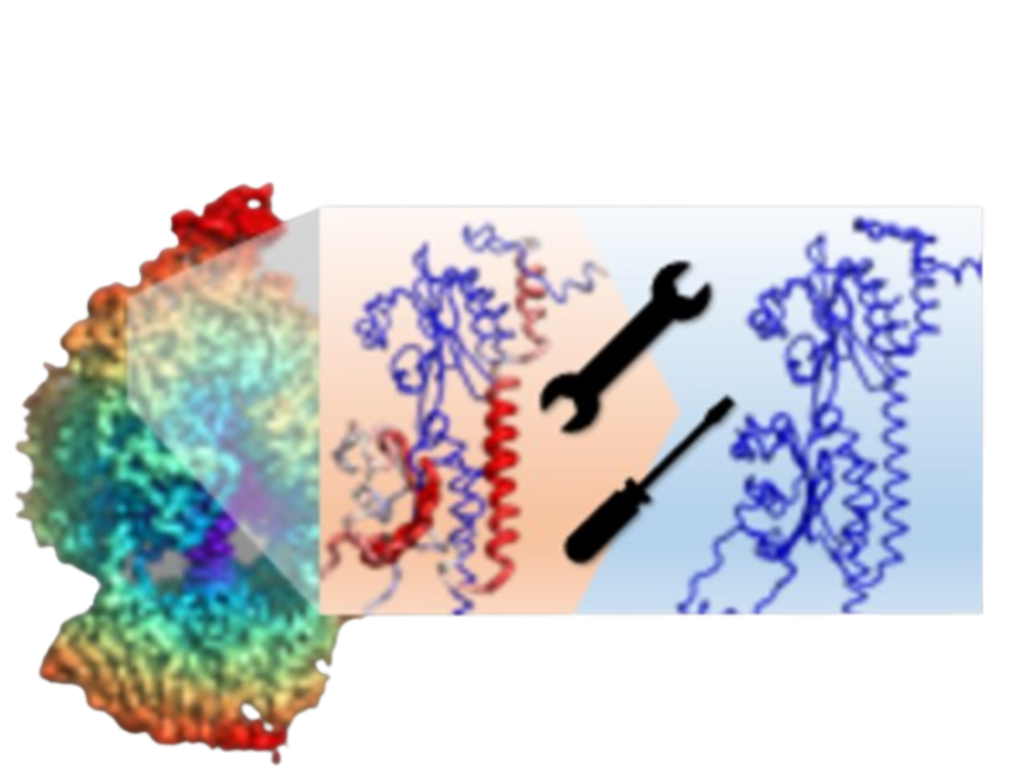
DAQ-refine is a tool that assesses protein models derived from cryo-EM maps (target resolution: 0-5
A) using the DAQ score and refine the identified regions with errors with modified AlphaFold2.
The output includes a .pdb file documenting the initially scored structure (by DAQ-Score) alongside
the refined structure generated by DAQ-Refine.
Our result webpage comprises three tabs: Results Visualization, Output Logs, and Job Configuration.
Results Visualization:
The 'Result Visualization' panel displays both the protein structure before and after refinement by
DAQ-Refine.
The B-factor column stores the DAQ(AA) score for each structure.
On the right-hand side, you can click the 'Download Outputs' button to acquire the modeled structure
in .pdb format.
The downloaded file includes the original input structure as the 1st model and the refined structure
by DAQ-Refine as the 2nd model.
Additionally, you can visualize the map online by clicking the "Show map" button.
Once loaded, the default contour level matches your input; however, you can make adjustments by
clicking the "..." button beside "isosurface."
Within the "Type: Isosurface" option, you can modify the iso-surface value and opacity by scrolling
through the bar for precise adjustments.
This feature allows you to assess the alignment between the modeled structure and the map.
The 3D models displayed in the panel are color-coded based on the DAQ(AA) score, ranging from red
(-1.0) to blue (1.0), employing a 19-residue sliding window.
Blue represents a good score, while red signifies a lower score from DAQ.
In MODEL1, the original model depicts all modeled positions colored according to the DAQ(AA)
score.
In MODEL2, the DAQ-Refine refined model portrays all modeled positions color-coded based on the
DAQ(AA) score.
Output Logs:
The 'Output Logs' panel compiles all outputs generated by the scripts.
If you're interested in monitoring the job's progress during execution, this section provides a
comprehensive overview.
Job Configuration:
In the 'Job Configuration' panel, you'll find the input parameters used for this specific job.
These records serve to maintain a log of your submitted input for reference.
For any troubleshooting needs: Should you encounter any issues, please don't hesitate to contact
us via
email to report the problems.
When sending an email, kindly use the subject line format 'DAQ-Refine problem: [jobid]', where
[jobid]
corresponds to the job displayed in the title.
This specific identification helps us efficiently locate and debug jobs in the backend, ensuring
a prompt response to your concerns.
Contact:
dkihara@purdue.edu, gterashi@purdue.edu.